Pro Stranu svobodných občanů jsem analyzoval výsledky krajských voleb v libereckém kraji. Měla na výsledek vliv kontaktní kampaň ve městě, známost jejich politiků, počet členů a příznivců z okolí, pojízdný billboard nebo něco úplně jiného? Jaké druhy akcí by strana pro příště měla lokálně pořádat a s jakou cílovou skupinou by měla dlouhodobě pracovat, aby dosáhla lepších výsledků?
Category: Články česky
Time Deposit Propensity Modeling Dataset
Time Deposit Propensity Modeling Dataset obsahuje údaje o 120 000 zákaznících bank. Cílovou proměnnou je údaj o tom, zda si zákazník otevřel termínovaný účet.
Cílem analýzy je na základě dostupných údajů predikovat, kteří zákazníci si otevřou termínovaný účet.
Atributy datasetu
Demografické
Pohlaví, věk (určen datem narození a referenčním datem), stav (ženatý/vdaná, rozvedený/á, svobodný/á…), počet dětí, pracovní pozice.
Finanční
Roční příjem, indikátor výplatního vztahu k bance, obchodního vztahu k bance.
Bankovní produkty
Účet, investiční produkty, pojištění, podnikatelská půjčka, hypotéka, spotřebitelská půjčka, kreditní karta.
Zůstatky
Výše účtu, výše financí v investičních produktech, výše financí v pojištění, výše podnikatelské půjčky, výše hypotéky, výše spotřebitelské půjčky, výše půjčky na kreditní kartě.
Transakce – počet
Počet transakcí na pobočce, počet výběrů z ATM, počet APS transakcí, počet transakcí telefonem, počet transakcí přes internet, počet výběrů za měsíc, počet plateb za měsíc, počet převodů za měsíc.
Transakce – objem
Objem zaplacených záloh za měsíc, objem výběrů, objem plateb, objem převodů.
Kreditní karta
Počet splátek, počet plateb za měsíc, počet nákupů za měsíc, počet výběrů za měsíc, objem plateb za měsíc, objem nákupů za měsíc, objem výběrů za měsíc.
Nedoplatky
Počet měsíců s nedoplatky.
Otevření termínovaného účtu
Cílová proměnná – otevřel si klient termínovaný účet?
Předzpracování dat
Hodnoty atributů
Hodnoty atributů jsem v první fázi hodnotil pomocí filtrů v MS Excel, následně pomocí statistik v RapidMiner. Mohl jsem tak identifikovat nelogické, chybějící či podezřelé hodnoty. Nejzajímavější z tohoto hlediska mi přišly hodnoty zaměstnání „default“ (17 pozorování). Pravděpodobně se jedná o nevyplněnou hodnotu. Druhou zajímavostí je 25 pozorování se záporným ročním příjmem. Kdyby tato hodnota chyběla, doplnil bych ji (buď průměrem nebo na základě regresní analýzy). Vzhledem k tomu, že je to hodnota nejspíš chybná (a u většiny z těchto pozorování se také vyskytuje podezřelá kategorie zaměstnání „default“), rozhodl jsem se tato pozorování do analýzy nezařadit. Důvodem pro toto rozhodnutí je také to, že nemám jak zjistit, jak tato data vznikla, takže pokud by se v analýze ukázala jako významná, stejně bych neměl možnost je interpretovat. Odstranění podezřelých dat z analýzy by nemělo zkreslit výsledky, vzhledem k tomu, že se jedná pouze o 0,02 % dat.
Agregace a normalizace
Nad daty jsem provedl následující výpočty a agregace.
- Výpočet věku
- Sumarizaci počtu produktů u banky.
- Součet pozitivního zůstatku v bankovních produktech.
- Normalizaci objemu pozitivního zůstatku oproti celkovému pozitivnímu zůstatku podle druhu (poměr).
- Součet negativního zůstatku (půjčky, záporný zůstatek na kreditní kartě) v bankovních produktech.
- Normalizaci objemu negativního zůstatku oproti celkovému negativnímu zůstatku podle druhu (poměr).
- Sumarizaci celkového počtu měsíčních transakcí.
- Normalizaci objemu transakcí podle druhu.
- Sumarizaci celkové aktivity kreditní karty.
- Normalizaci objemu aktivit kreditní karty podle druhu.
Normalizovaná data mají mnohem větší výpovědní hodnotu, než data původní, protože lépe rozdělují zákazníky podle jejich chování. Pro vysvětlení uvažujme zákazníky A, B, C s následujícími parametry transakčního objemu a kanálů, jimiž byl tento objem učiněn.

Pokud bychom chtěli tyto tři zákazníky rozdělit do dvou shluků podle využití kanálu 2, na nenormalizovaných datech by v prvním shluku skončil zákazník A a ve druhém shluku zákazníci B a C. To je ovšem evidentně špatně, protože chování zákazníků A a B je shodné (kanálem 2 uskutečnili 20 % transakcí), zatímco chování zákazníka C je odlišné (kanálem 2 uskutečnil 60% transakcí).
Explorační analýza
Explorační analýzu jsem provedl pomocí statistik v programu RapidMiner. Nejzajímavější výsledky ohledně rozdělení četností a hodnot jednotlivých proměnných následují:
- Třetina žen, dvě třetiny mužů.
- Průměrný věk 42 let, rozptyl věku 19-69 let.
- Nejvíc klientů je ženatých/vdaných (60 %) a single (30 %), zbylých 10 % je rozvedeno nebo ovdovělých.
- Průměr dětí klienta je 0,7, maximální počet dětí je 12.
- Podle druhu pracovního poměru je 56 % zaměstnanců, 17 % vlastníků firmy, nejméně je pak nezaměstnaných (5,2 %) a podnikatelů (3,5 %).
- Průměrný roční příjem je 44 744.
- Nejvíc klientů má tři bankovní produkty (průměr je 2,7).
- Průměr zůstatku na kladných produktech je 688 s vysokým rozptylem (1492), největší sumu mají klienti na běžném/spořicím účtu (71 %).
- Průměrný počet měsíčních transakcí je 3,75, průměrná částka je 927 za měsíc, rozptyl je 3572.
- Průměrná částka transferů kreditní kartou 208.
- Nedoplatky – více než 100 000 klientů nedlužilo vůbec, přes 3000 dluží celý rok.
- Nejdůležitější je rozdělení Time deposit flagu (1337 T, 118638 F), tedy termínovaný účet si otevřelo pouze 1,11 % klientů. Na tuto nevyváženost je zapotřebí si dát pozor při tvorbě klasifikačního modelu.
Modelování
Cílem je vytvořit model, který dokáže co nejlépe klasifikovat otevření termínovaného účtu, tedy dosáhnout maximální hodnoty parametru recall pro hodnotu cílového atributu True za současně co největší celkové přesnosti modelu. Recall je poměr TP predikcí a celkových pozitivních dat. Dataset rozdělím na trénovací a testovací data v poměru 70:30.
Rozhodovací strom
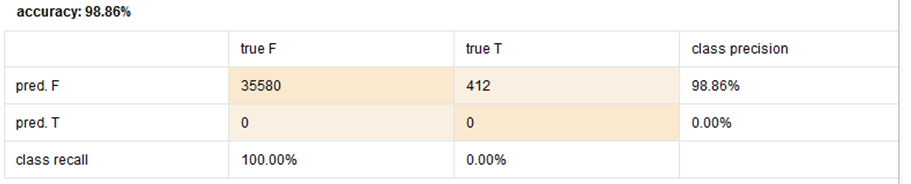
Základní nastavení stromu nezafungovalo. Strom predikuje všem hodnotám false, což sice znamená prakticky 99% úspěšnost, ale recall cílové třídy je 0. Problémem je nevybalancovanost dat. Pokud jsou data nevybalancovaná, class recall se blíží celkovému zastoupení třídy v datech. Použil jsem tedy sampling tak, aby data byla vybalancovaná. Dále jsem změnil kritérium pro umisťování uzlů. Defaultní nastavení je information gain, který umisťuje uzly s minimální entropií. Má tedy tendenci vybírat atributy s velkým množstvím hodnot. Místo information gain použiji accuracy. Těmito dvěma kroky se predikční model podstatně zlepšil. Přesnost predikce cílové třídy je 64 %, recall 62,5 %.

Samotný strom je vytvořen pouze na základě jednoho kritéria – celkové sumy na kladných bankovních produktech (účet, pojištění, investice).
V případě rozhodování na základě více kritérií by se přesnost stromu mohla zlepšit. Zakážu tedy prepruning stromu a maximální hloubku stromu nastavím na 5. Přesnost i recall se nepatrně zlepšily. Další vylepšení modelu by mohlo spočívat v manuálním nastavení hodnot prepruningu či použití jiného druhu rozhodovacího stromu. Tento výsledek modelu však nyní považuji za dostatečný.
Výsledný model
Pro přehlednost byla vybrána pouze rozhodovací pravidla, určující třídu T.
Total + balance > 499.697
| CC % > 0.022
| | Total + balance > 2721.464
| | | Saving % > 0.047: T {F=6, T=17}
| | Total + balance ≤ 2721.464
| | | CC purchase % > 0.601: T {F=2, T=8}
| CC % ≤ 0.022
| | Total – balance > -6187.096
| | | Age > 26.500: T {F=306, T=733}
| | Total – balance ≤ -6187.096
| | | Age ≤ 39.500: T {F=0, T=2}
Total + balance ≤ 499.697
| Total_Income > 78051
| | Payment trans % > 0.018
| | | Trasaction count > 11.333: T {F=1, T=4}
| | Payment trans % ≤ 0.018
| | | Total – balance > -405.913: T {F=37, T=126}
| Total_Income ≤ 78051
| | Total products > 0.500
| | | Occupation_Category = Self-Employees: T {F=16, T=23}
| | Total products ≤ 0.500: T {F=0, T=13}
Úspěšnost modelu je potřeba ověřit i na nenasamplovaných datech.

Shrnutí a vyhodnocení výsledků
Data jsem transformoval a normalizoval a na vyvážený vzorek dat jsem aplikoval algoritmus rozhodovacího stromu, který vybíral uzly podle přesnosti, neaplikoval prepruning a měl 5 úrovní. Tento strom dokázal z datasetu vybrat jednu třetinu klientů, mezi nimiž se nacházelo 70% klientů, kteří si otevřeli termínovaný vklad. Klienty, kteří nejvíce inklinují k otevření termínovaného vkladu, byli klienti s následujícími parametry: – Celkový finanční zůstatek na kladných produktech větší než 2721 dolarů; úspory na běžném či spořicím účtu tvoří více než 5% této částky; úspora na kreditní kartě je větší než 2% výše půjček. – Starší než 26 let; rozdíl zůstatku na kreditní kartě a půjček není větší než 6187 dolarů; poměr peněz na kreditní kartě a půjček je menší než 2,2 %. – Rozdíl zůstatku na kreditní kartě a v půjčkách není větší než 406 dolarů, platby z účtu tvoří méně než 1,8 % celkových transakcí, celkový roční příjem je větší než 78 000 dolarů, v kladných bankovních produktech mají méně než 500 dolarů. – V kladných bankovních produktech mají méně než 500 dolarů, celkový roční příjem je menší než 78 000 dolarů, ještě nemají žádný bankovní produkt (kromě běžného/spořicího účtu). – V kladných bankovních produktech mají méně než 500 dolarů, celkový roční příjem je menší než 78 000 dolarů, již mají nějaký bankovní produkt a jsou podnikatelé.
Aplikace
Aplikace a další ladění modelů parametru by v praxi závisely na rozhodnutí managementu. Mým doporučením by bylo na klienty ve vytyčeném segmentu cílit marketing zaměřený na otevření termínovaného vkladu. Přesnost cílení se v každém případě pohybuje mezi 2 a 3 procenty, což je 2 – 2,5 krát větší přesnost, než pokud bychom model neaplikovali a cílili naslepo. Na rozhodnutí managementu by bylo, zda chtějí zacílit na větší skupinu potenciálních klientů i za cenu cílení na nepotenciální klienty. Pokud by tomu tak bylo, rozšíření rozhodovacího stromu o další patra by dokázalo tento požadavek splnit. Oslovení 45 000 klientů (výsledek stromu o 12 patrech) dokáže pokrýt 80% klientů se záměrem účet otevřít.
Česká politika očima Twitteru
Tl;dr
- Strany se na twitteru nedělí podle politických teorií (pravice/levice, konzervativní/liberální), ale spíše na protest/establishment (lze interpretovat i jako malé/velké s několika výjimkami).
- Politická scéna na twitteru se dá rozdělit na
- Česká politika – pravice
- Europolitika
- Česká politika – levice + střed
- ? (Vláda, celebrity, populisté)
- Sekty (Svobodní, Zelení…)
- Nejvýraznější osobností je Andrej Babiš, který je ale brán víc jako celebrita než jako politik
Sociální sítě dávají jasnou odpověď, která nemusí být přesná
Při hledání odpovědí na politické otázky s využitím sociálních sítí nesmíme zapomenout na specifika podobných analýz. Prvním je fakt, že závěry nelze zobecnit na celou populaci, protože se nejedná o reprezentativní vzorek obyvatelstva. Na českém twitteru se nachází především nejmladší generace (70% uživatelů je mladších 30 let), městská, vzdělanější a mužská část populace (v Česku 70 % mužů a 30 % žen). Celkový počet českých uživatelů twitteru se pohybuje mezi 300 a 500 tisíci uživateli, konkrétní odhady se rozcházejí.
Celebrity politického twitteru
Největší celebritou českého politického twitteru je s obrovskou převahou Andrej Babiš. Počet jeho followerů překonal letos na jaře 200 000. Babišovi a jeho PR týmu se navíc daří toto číslo konstantně navyšovat, od prosince 2015 získal více než 30 000 nových followerů. Odstup dalších politiků je značný. Oficiální účet Karla Schwarzenberga má lehce přes 30 000 followerů, které získal především během prezidentských voleb a od té doby se tento počet nemění. V první desítce co do počtu followerů najdeme třeba ještě Miroslava Kalouska, Bohuslava Sobotku, Pavla Bělobrádka, Petra Fialu či Jiřího Ovčáčka, který na twitteru podle vlastních slov oficiálně reprezentuje hrad. Nikdo z nich však nemá ani desetinu followerů Andreje Babiše.
Vliv twitterových účtů na společenské dění
Reálný vliv twitterového účtu na společenské dění se však nedá měřit jen počtem followerů. V úvahu musíme vzít i cílovou skupinu, kterou politik na twitteru oslovuje. Zde je například mezi účty Andreje Babiše a Jiřího Ovčáčka markantní rozdíl. Zatímco Andrej Babiš cílí na „běžného uživatele“ podobně jako na facebooku, Ovčáček používá twitter více jako nástroj komunikace s médii, což zvyšuje citovanost i reálný dosah jeho účtu. Zatímco 89 % followerů Andreje Babiše nesleduje žádného jiného českého politika, u Jiřího Ovčáčka je to pouze 27 %.
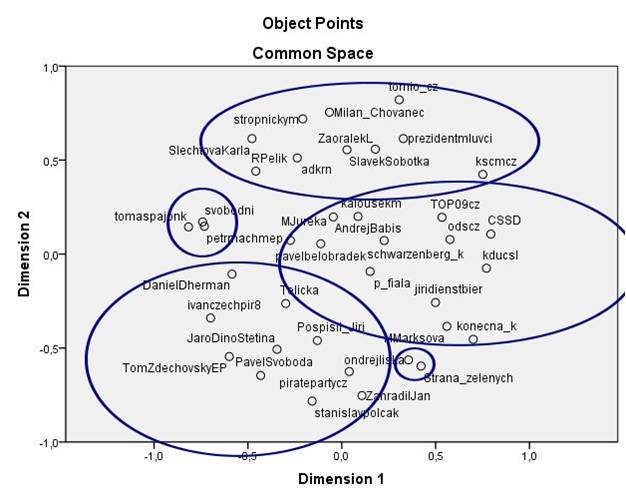
Politická mapa
Cílem mé analýzy bylo vytvořit politickou mapu, která by znázorňovala, jak k sobě mají jednotliví politici blázko. Jedním ze základních ukazatelů blízkosti na sociálních sítích je podíl společných přátel (na facebooku) nebo followerů (na twitteru). Abych získal lépe vypovídající výsledky, vyřadil jsem z analýzy followery, u kterých se dá předpokládat profesní zájem o problematiku (novináři, pracovníci v PR a marketingu, političtí analytici apod.) a jejichž following nemůže být žádným způsobem vyjádřením politických sympatií nebo osobního zájmu. V případě českého twitteru se jedná o skupinu asi 3000 followerů, kteří sledují více než pět politických účtů napříč celým spektrem.
Blízkost politických stran
Strany v tabulce jsem seřadil podle obecného chápání levice – pravice. Pokud by na Twitteru platilo, že se uživatelé dělí na tyto dva tábory, pak by tmavá část měla být podél diagonály (případně tmavá oblast vlevo nahoře a vpravo dole). To evidentně neplatí.
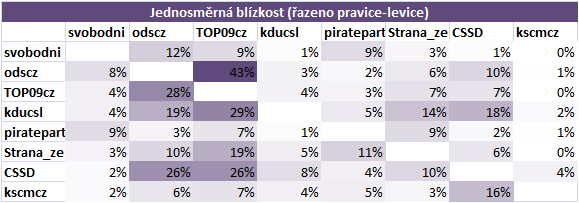
Nejlepší řazení, které vytvořilo tmavý shluk vpravo dole, je vidět na dalším obrázku. Nejpravděpodobnější interpretace výsledku je taková, že strany establishmentu (ČSSD, ODS, TOP09, KDUČSL) navzájem sdílejí svůj potenciální elektorát, zatímco strany, které se prezentují jako protestní (Svobodní, Zelení, Piráti, KSČM), mají úzce vyhraněnou skupinu fanoušků, kterou s ostatními stranami nesdílejí.
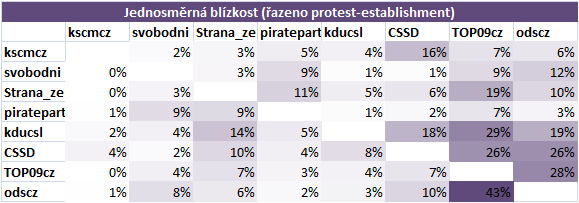
Úzké zaměření fanoušků protestních stran je vidět na tomto grafu. 70% followerů Svobodných, Pirátů a komunistů nesleduje žádnou jinou stranu, zatímco více než polovina fanoušků ČSSD, ODS a KDUČSL sleduje i jiné strany.

Výsledky, viditelné v matici blízkostí, jsou potvrzeny i hierarchickým shlukováním. Všimněme si, že strom se u protestních stran spojuje mnohem výše, než u stran establishmentu. To opět potvrzuje silné propojení fanoušků establishmentových stran a úzké zaměření fanoušků stran protestních.
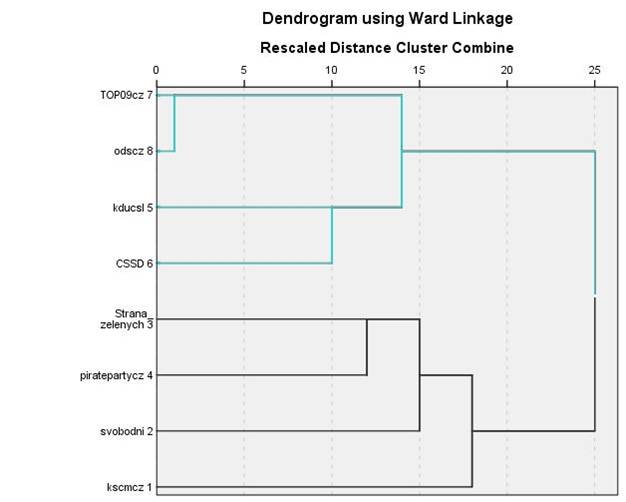
Blízkost politiků
Do druhé části analýzy jsem kromě politických stran zařadil i nejvlivnější twitterové účty politiků. Na tyto účty jsem opět aplikoval metodu hierarchického shlukování. Vzniklo následujících pět shluků:
Česká pravice
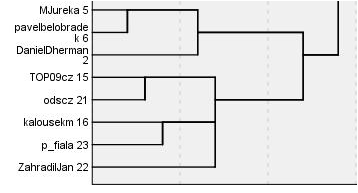
Europolitika
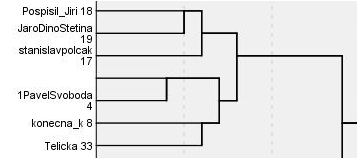
Česká levice a střed
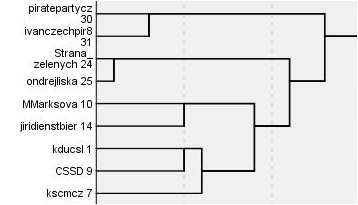
Vláda, celebrity, populisti
Do jednoho shluku zde spadl Andrej Babiš, Adriana Krnáčová, Tomio Okamura a Jiří Ovčáček – pro mě osobně nejzajímavější výsledek celé analýzy 🙂
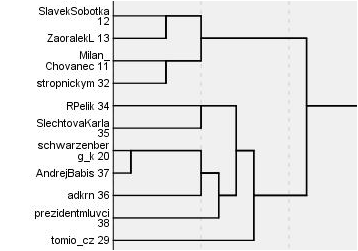
Politické sekty
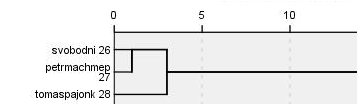
Vícerozměrné škálování
Metoda vícerozměrného škálování vytváří 2D mapu, která je ovšem méně přesná, než zobrazení ve stromu hierarchického shlukování. Dává však velmi podobné výsledky, jako předchozí metoda.
Americké primárky – analýza sentimentu
Tl;dr
Cílem experimentu bylo porovnat jednoduchý (akademický Lexicoder) a sofistikovaný (komerční Semantria od Lexalytics) nástroj na analýzu sentimentu. Samotnou analýzu jsem dělal nad tweety o Donaldu Trumpovi, Hillary Clinton a Bernie Sandersovi (květen 2016). Lexicoder vrátil na tweetech jasné souhrnné výsledky, které však postrádají podrobnost. Hillary a Bernie mají celkově pozitivní sentiment tweetů (+5%), zatímco Donald negativní (-3%). Tweety o Berniem jsou však celkově o něco méně emocionálně zabarvené než tweety o Donaldovi a Hillary. Semantria od Lexalytics se ukázala nevhodnou pro tento typ datasetu.
Analýza sentimentu
je studie stanovisek, citů, subjektivity, postojů, hodnocení, dojmů, názorů a emocí vyjádřených v textu. Datovým zdrojem může být jakýkoli dokument, pro praktické použití jsou používané především uživatelské recenze, diskusní příspěvky, zprávy, komentáře či příspěvky na sociálních sítích (twitter, facebook).
Dolování nalezených názorů může probíhat buď na úrovni jednotlivých částí textu (dokument, odstavec, věta) nebo na úrovni aspektů, kdy přiřazujeme sentiment určitým entitám v textu.
Dolování sentimentu na úrovni dokumentu
Dolování sentimentu souhrnně z částí textu je založené na jednoduchém principu. Text předzpracujeme na jednotlivé tokeny. Ty pak porovnáváme se slovníkem pozitivních a negativních výrazů pro danou doménu. Celkové zabarvení textu je pak dáno poměrem pozitivních a negativních výrazů. Touto technikou lze určit nejen pozitivitu/negativitu dokumentu, ale i jeho subjektivitu (poměr součtu pozitivních a negativních výrazů vůči celkovému rozsahu dokumentu). Výsledky této metody lze zpřesnit v zásadě trojím způsobem: 1. Použít kvalitnější slovník, lépe přizpůsobený pro danou doménu. 2. Ve slovníku definovat váhy výrazů (např. nedobrý -> špatný -> příšerný). 3. Uvažovat i kontext výrazu a zesilující/zeslabující slova (velmi, opravdu, moc, příliš).
Dolování sentimentu na úrovni aspektů
Pro lepší představu uvažujme příklad recenze mobilního telefonu. Úkolem je nestrukturovaný text strukturovat. Prvním krokem je z textu extrahovat entity a stromovou strukturu jejich aspektů, kterým následně přiřazujeme konkrétní sentiment. V našem příkladu je entitou (kořenovým elementem stromu aspektů) mobilní telefon. První úrovní aspektů může být např. fotoaparát a baterie, listy pak čočka a kvalita fotografií s bleskem (pro rodičovský uzel fotoaparát), respektive velikost baterie a výdrž baterie (pro rodičovský uzel baterie).
Strukturování textu potom spočívá v extrakci uspořádaných pětic informací: (entita, aspekt, sentiment, zdroj názoru, čas názoru). V našem případě taková pětice může vypadat následovně (iPhone 6, obrazovka, +, mobilmania.cz, 12. 5. 2016). V případě politické domény by to například bylo (Donald Trump, vztah k ženám, -, tweet, 12.5.2016).
Vytváření těchto vektorů využívá mnoho známých postupů text miningu. Entity jsou rozpoznávány pomocí NER (rozpoznávání pojmenovaných entit), aspekty pomocí IE (extrakce informací), sentiment pomocí SI (identifikace sentimentu), zdroj a čas názoru potom pomocí DE (extrakce dat). Vytváření těchto vektorů se také potýká s klasickými problémy text miningu jako je řešení koreferencí, problém synonym apod. Pro úspěch je klíčovým faktorem znalost domény a přizpůsobení modelu této doméně.
Dataset
Pro svou práci jsem použil data z probíhajících amerických primárek. Z twitteru jsem pomocí veřejného Twitter streaming API stáhnul obsahy tweetů, filtrované podle následující tabulky:

Při použití dat z twitteru je vždy potřeba pamatovat na jejich specifické vlastnosti. Prvním rysem je, že obsahují mnoho zkratek, hovorových a nespisovných výrazů a překlepů, což znamená větší nároky na přípravu slovníku. Druhou zvláštností, která se projevila na mém datasetu, je fakt, že nelze vždy s přesností určit, o kom přesně tweet pojednává, protože ve 140 znacích často chybí slovesa a označeno v něm bývá více kandidátů. Tweetů, kde je označen víc než jeden kandidát, byla v mém datasetu téměř třetina (největší průnik měl pochopitelně Donald Trump a Hillary Clinton). Tyto tweety jsem tak přiřadil k oběma kandidátům.
Lexicoder – výsledky
Z hlediska výše popsaných algoritmů se jedná o nejjednodušší dolování sentimentu na úrovni celého dokumentu bez vah výrazů.

Výsledky zpracování sentimentu nejsou překvapující. Hillary Clinton a Bernie Sanders mají celkově pozitivní sentiment, zatímco Donald Trump negativní, Tyto výsledky podle mě dobře odpovídají jejich mediálnímu obrazu. Zajímavým zjištěním je, že tweety o Hillary Clinton a Donaldu Trumpovi jsou přibližně o pětinu emocionálněji zabarvené než tweety o Berniem Sandersovi.
Semantria – výsledky
Komerční program Semantria od Lexalytics funguje jako add-in do programu MS Excel. Nabízí mnohem větší škálu možností – z těch nejčastěji používaných je to, kromě analýzy sentimentu, generování frází, analýza slov, extrakce záměrů, entit, témat, aspektů, generování automatického shrnutí dokumentů, word-cloudů, asociačních pravidel a další.
Pro výpočet sentimentu tweetů jsem tweety sloučil do celků o cca 2000 znacích, což je maximální délka dokumentu v trial verzi Semantria. Například generování summary ze stoznakového tweetu mi nedává logicky smysl, proto mě zajímalo, jak se Semantria vypořádá s dokumentem, tvořeným více tweety.
Výstupy analýzy ze Semantria

V ukázce je vidět, že téma „Raising taxes“ a „Raising everyone“ v jednom z dokumentů bylo hodnoceno pozitivním sentimentem. Část dokumentu, kde se tato slova vyskytují, zní následovně:
„Trump’s Raising taxes on the rich is Code: for raising everyone’s taxes and expanding Big Govt control of the people. NeverTrump“
Ohodnocení sentimentu tématu je tedy evidentně chybné. Zdá se, že hlavním problémem analýzy je to, že věty z twitteru nedávají gramaticky smysl a mnohdy se nedají oddělit, protože nejsou ukončeny tečkou. Proto jsem se rozhodl pro další vyzkoušení práce s programem použít novinové články z US médií, tedy manuálně posoudit článek z Weekly Standard. Jeho hlavním tématem je neschopnost mediálně známé a oblíbené Hillary odpárat z primárek před nedávnem naprosto neznámého „socialistického sedmdesátníka“. Článek se zamýšlí nad důvody této skutečnosti a končí odstavcem:
„At the same time that Sanders dominates Clinton with measures of all the personal attributes, he’s pushed her to a dead heat in nationwide polling and has mounted an unlikely resilient challenge to her coronation as the Democratic nominee. Much of it is because Sanders has tapped into the party base’s rebelliousness, more than any Democratic candidate in any recent election. In so doing, he has exploited Clinton’s support as lukewarm.“
Shrnutí odstavce: Sanders je mnohem rebelštějším kandidátem než kterýkoli demokrat před ním. To je důvod, proč tak ohrozil její vítězství v primárkách („korunovaci kandidátem Demokratů“).
Pokud bych měl extrahovat entity a sentiment s nimi spojený, nejspíš by vyhrál Sanders, díky těmto výrokům: – Sanders dominates Clinton – He pushed her to a dead heat – He has tapped into the party base’s rebelliousness – He exploited her support as lukewarm
Sentiment odstavce a entit: Celkový sentiment odstavce byl označen jako mírně negativní.
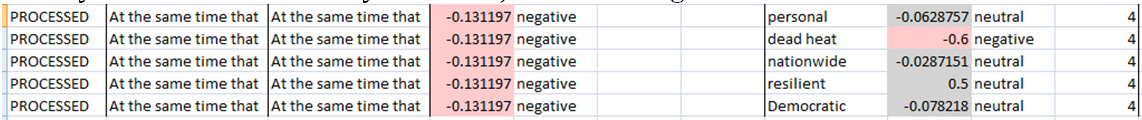
Z extrahovaných témat byl záporný sentiment přiřazen výrazu „dead heat“ a kladný výrazu „resilient“, sentiment ostatních témat je neutrální.
Extrakci témat hodnotím spíš jako neúspěšnou. Dle mého názoru by měly být tématem odstavce slova: Sanders, Clinton, polling, lukewarm support. Ani v dalších odstavcích se mi extrahovaná témata nezdají vždy správná. U jednodušších případů je však určení sentimentu témat evidentně správné, u složitějších pak rozporné.