Time Deposit Propensity Modeling Dataset obsahuje údaje o 120 000 zákaznících bank. Cílovou proměnnou je údaj o tom, zda si zákazník otevřel termínovaný účet.
Cílem analýzy je na základě dostupných údajů predikovat, kteří zákazníci si otevřou termínovaný účet.
Atributy datasetu
Demografické
Pohlaví, věk (určen datem narození a referenčním datem), stav (ženatý/vdaná, rozvedený/á, svobodný/á…), počet dětí, pracovní pozice.
Finanční
Roční příjem, indikátor výplatního vztahu k bance, obchodního vztahu k bance.
Bankovní produkty
Účet, investiční produkty, pojištění, podnikatelská půjčka, hypotéka, spotřebitelská půjčka, kreditní karta.
Zůstatky
Výše účtu, výše financí v investičních produktech, výše financí v pojištění, výše podnikatelské půjčky, výše hypotéky, výše spotřebitelské půjčky, výše půjčky na kreditní kartě.
Transakce – počet
Počet transakcí na pobočce, počet výběrů z ATM, počet APS transakcí, počet transakcí telefonem, počet transakcí přes internet, počet výběrů za měsíc, počet plateb za měsíc, počet převodů za měsíc.
Transakce – objem
Objem zaplacených záloh za měsíc, objem výběrů, objem plateb, objem převodů.
Kreditní karta
Počet splátek, počet plateb za měsíc, počet nákupů za měsíc, počet výběrů za měsíc, objem plateb za měsíc, objem nákupů za měsíc, objem výběrů za měsíc.
Nedoplatky
Počet měsíců s nedoplatky.
Otevření termínovaného účtu
Cílová proměnná – otevřel si klient termínovaný účet?
Předzpracování dat
Hodnoty atributů
Hodnoty atributů jsem v první fázi hodnotil pomocí filtrů v MS Excel, následně pomocí statistik v RapidMiner. Mohl jsem tak identifikovat nelogické, chybějící či podezřelé hodnoty. Nejzajímavější z tohoto hlediska mi přišly hodnoty zaměstnání „default“ (17 pozorování). Pravděpodobně se jedná o nevyplněnou hodnotu. Druhou zajímavostí je 25 pozorování se záporným ročním příjmem. Kdyby tato hodnota chyběla, doplnil bych ji (buď průměrem nebo na základě regresní analýzy). Vzhledem k tomu, že je to hodnota nejspíš chybná (a u většiny z těchto pozorování se také vyskytuje podezřelá kategorie zaměstnání „default“), rozhodl jsem se tato pozorování do analýzy nezařadit. Důvodem pro toto rozhodnutí je také to, že nemám jak zjistit, jak tato data vznikla, takže pokud by se v analýze ukázala jako významná, stejně bych neměl možnost je interpretovat. Odstranění podezřelých dat z analýzy by nemělo zkreslit výsledky, vzhledem k tomu, že se jedná pouze o 0,02 % dat.
Agregace a normalizace
Nad daty jsem provedl následující výpočty a agregace.
- Výpočet věku
- Sumarizaci počtu produktů u banky.
- Součet pozitivního zůstatku v bankovních produktech.
- Normalizaci objemu pozitivního zůstatku oproti celkovému pozitivnímu zůstatku podle druhu (poměr).
- Součet negativního zůstatku (půjčky, záporný zůstatek na kreditní kartě) v bankovních produktech.
- Normalizaci objemu negativního zůstatku oproti celkovému negativnímu zůstatku podle druhu (poměr).
- Sumarizaci celkového počtu měsíčních transakcí.
- Normalizaci objemu transakcí podle druhu.
- Sumarizaci celkové aktivity kreditní karty.
- Normalizaci objemu aktivit kreditní karty podle druhu.
Normalizovaná data mají mnohem větší výpovědní hodnotu, než data původní, protože lépe rozdělují zákazníky podle jejich chování. Pro vysvětlení uvažujme zákazníky A, B, C s následujícími parametry transakčního objemu a kanálů, jimiž byl tento objem učiněn.

Pokud bychom chtěli tyto tři zákazníky rozdělit do dvou shluků podle využití kanálu 2, na nenormalizovaných datech by v prvním shluku skončil zákazník A a ve druhém shluku zákazníci B a C. To je ovšem evidentně špatně, protože chování zákazníků A a B je shodné (kanálem 2 uskutečnili 20 % transakcí), zatímco chování zákazníka C je odlišné (kanálem 2 uskutečnil 60% transakcí).
Explorační analýza
Explorační analýzu jsem provedl pomocí statistik v programu RapidMiner. Nejzajímavější výsledky ohledně rozdělení četností a hodnot jednotlivých proměnných následují:
- Třetina žen, dvě třetiny mužů.
- Průměrný věk 42 let, rozptyl věku 19-69 let.
- Nejvíc klientů je ženatých/vdaných (60 %) a single (30 %), zbylých 10 % je rozvedeno nebo ovdovělých.
- Průměr dětí klienta je 0,7, maximální počet dětí je 12.
- Podle druhu pracovního poměru je 56 % zaměstnanců, 17 % vlastníků firmy, nejméně je pak nezaměstnaných (5,2 %) a podnikatelů (3,5 %).
- Průměrný roční příjem je 44 744.
- Nejvíc klientů má tři bankovní produkty (průměr je 2,7).
- Průměr zůstatku na kladných produktech je 688 s vysokým rozptylem (1492), největší sumu mají klienti na běžném/spořicím účtu (71 %).
- Průměrný počet měsíčních transakcí je 3,75, průměrná částka je 927 za měsíc, rozptyl je 3572.
- Průměrná částka transferů kreditní kartou 208.
- Nedoplatky – více než 100 000 klientů nedlužilo vůbec, přes 3000 dluží celý rok.
- Nejdůležitější je rozdělení Time deposit flagu (1337 T, 118638 F), tedy termínovaný účet si otevřelo pouze 1,11 % klientů. Na tuto nevyváženost je zapotřebí si dát pozor při tvorbě klasifikačního modelu.
Modelování
Cílem je vytvořit model, který dokáže co nejlépe klasifikovat otevření termínovaného účtu, tedy dosáhnout maximální hodnoty parametru recall pro hodnotu cílového atributu True za současně co největší celkové přesnosti modelu. Recall je poměr TP predikcí a celkových pozitivních dat. Dataset rozdělím na trénovací a testovací data v poměru 70:30.
Rozhodovací strom
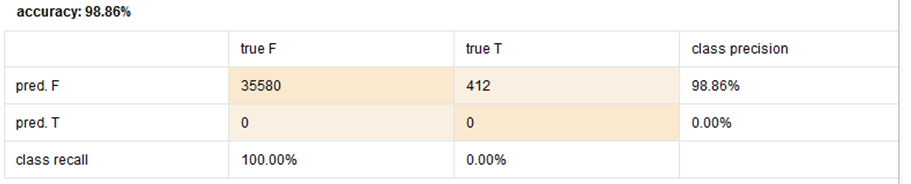
Základní nastavení stromu nezafungovalo. Strom predikuje všem hodnotám false, což sice znamená prakticky 99% úspěšnost, ale recall cílové třídy je 0. Problémem je nevybalancovanost dat. Pokud jsou data nevybalancovaná, class recall se blíží celkovému zastoupení třídy v datech. Použil jsem tedy sampling tak, aby data byla vybalancovaná. Dále jsem změnil kritérium pro umisťování uzlů. Defaultní nastavení je information gain, který umisťuje uzly s minimální entropií. Má tedy tendenci vybírat atributy s velkým množstvím hodnot. Místo information gain použiji accuracy. Těmito dvěma kroky se predikční model podstatně zlepšil. Přesnost predikce cílové třídy je 64 %, recall 62,5 %.

Samotný strom je vytvořen pouze na základě jednoho kritéria – celkové sumy na kladných bankovních produktech (účet, pojištění, investice).
V případě rozhodování na základě více kritérií by se přesnost stromu mohla zlepšit. Zakážu tedy prepruning stromu a maximální hloubku stromu nastavím na 5. Přesnost i recall se nepatrně zlepšily. Další vylepšení modelu by mohlo spočívat v manuálním nastavení hodnot prepruningu či použití jiného druhu rozhodovacího stromu. Tento výsledek modelu však nyní považuji za dostatečný.
Výsledný model
Pro přehlednost byla vybrána pouze rozhodovací pravidla, určující třídu T.
Total + balance > 499.697
| CC % > 0.022
| | Total + balance > 2721.464
| | | Saving % > 0.047: T {F=6, T=17}
| | Total + balance ≤ 2721.464
| | | CC purchase % > 0.601: T {F=2, T=8}
| CC % ≤ 0.022
| | Total – balance > -6187.096
| | | Age > 26.500: T {F=306, T=733}
| | Total – balance ≤ -6187.096
| | | Age ≤ 39.500: T {F=0, T=2}
Total + balance ≤ 499.697
| Total_Income > 78051
| | Payment trans % > 0.018
| | | Trasaction count > 11.333: T {F=1, T=4}
| | Payment trans % ≤ 0.018
| | | Total – balance > -405.913: T {F=37, T=126}
| Total_Income ≤ 78051
| | Total products > 0.500
| | | Occupation_Category = Self-Employees: T {F=16, T=23}
| | Total products ≤ 0.500: T {F=0, T=13}
Úspěšnost modelu je potřeba ověřit i na nenasamplovaných datech.

Shrnutí a vyhodnocení výsledků
Data jsem transformoval a normalizoval a na vyvážený vzorek dat jsem aplikoval algoritmus rozhodovacího stromu, který vybíral uzly podle přesnosti, neaplikoval prepruning a měl 5 úrovní. Tento strom dokázal z datasetu vybrat jednu třetinu klientů, mezi nimiž se nacházelo 70% klientů, kteří si otevřeli termínovaný vklad. Klienty, kteří nejvíce inklinují k otevření termínovaného vkladu, byli klienti s následujícími parametry: – Celkový finanční zůstatek na kladných produktech větší než 2721 dolarů; úspory na běžném či spořicím účtu tvoří více než 5% této částky; úspora na kreditní kartě je větší než 2% výše půjček. – Starší než 26 let; rozdíl zůstatku na kreditní kartě a půjček není větší než 6187 dolarů; poměr peněz na kreditní kartě a půjček je menší než 2,2 %. – Rozdíl zůstatku na kreditní kartě a v půjčkách není větší než 406 dolarů, platby z účtu tvoří méně než 1,8 % celkových transakcí, celkový roční příjem je větší než 78 000 dolarů, v kladných bankovních produktech mají méně než 500 dolarů. – V kladných bankovních produktech mají méně než 500 dolarů, celkový roční příjem je menší než 78 000 dolarů, ještě nemají žádný bankovní produkt (kromě běžného/spořicího účtu). – V kladných bankovních produktech mají méně než 500 dolarů, celkový roční příjem je menší než 78 000 dolarů, již mají nějaký bankovní produkt a jsou podnikatelé.
Aplikace
Aplikace a další ladění modelů parametru by v praxi závisely na rozhodnutí managementu. Mým doporučením by bylo na klienty ve vytyčeném segmentu cílit marketing zaměřený na otevření termínovaného vkladu. Přesnost cílení se v každém případě pohybuje mezi 2 a 3 procenty, což je 2 – 2,5 krát větší přesnost, než pokud bychom model neaplikovali a cílili naslepo. Na rozhodnutí managementu by bylo, zda chtějí zacílit na větší skupinu potenciálních klientů i za cenu cílení na nepotenciální klienty. Pokud by tomu tak bylo, rozšíření rozhodovacího stromu o další patra by dokázalo tento požadavek splnit. Oslovení 45 000 klientů (výsledek stromu o 12 patrech) dokáže pokrýt 80% klientů se záměrem účet otevřít.